DISTRIBUCIÓN DE UNA VARIABLE ALEATORIA CONTINUA
Si la variable aleatoria es continua, hay infinitos valores posibles de la variable y entra cada dos de ellos se podrían definir infinitos valores.
Cuando la variable aleatoria sea continua hablaremos de función de densidad. Sea X una variable aleatoria continua, se llama función de densidad y se representa como f(x) a una función no negativa definida sobre la recta real.
FUNCIÓN DE DISTRIBUCIÓN La función de distribución describe el comportamiento probabilístico de una variable aleatoria X asociada a un experimento aleatorio y se representa como: F(x) ó Fx Para estudiar la función de distribución distinguiremos entre el caso discreto y el caso continuo.
Cuando la variable aleatoria sea continua hablaremos de función de densidad. Sea X una variable aleatoria continua, se llama función de densidad y se representa como f(x) a una función no negativa definida sobre la recta real.
FUNCIÓN DE DISTRIBUCIÓN La función de distribución describe el comportamiento probabilístico de una variable aleatoria X asociada a un experimento aleatorio y se representa como: F(x) ó Fx Para estudiar la función de distribución distinguiremos entre el caso discreto y el caso continuo.

DISTRIBUCIÓN NORMAL
La distribución normal fue reconocida por primera vez por el francés Abraham de Moivre (1667-1754). Posteriormente, Carl Friedrich Gauss (1777-1855) elaboró desarrollos más profundos y formuló la ecuación de la curva; de ahí que también se la conozca, más comúnmente, como la"campana de Gauss". La distribución de una variable normal está completamente determinada por dos parámetros, su media y su desviación estándar, denotadas generalmente pory
. Con esta notación, la densidad de la normal viene dada por la ecuación:
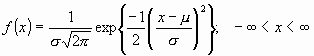
que determina la curva en forma de campana que tan bien conocemos. Así, se dice que una característicasigue una distribución normal de media
y varianza
, y se denota como
, si su función de densidad viene dada por la Ecuación 1.
Al igual que ocurría con un histograma, en el que el área de cada rectángulo es proporcional al número de datos en el rango de valores correspondiente si, tal y como se muestra en la figura, en el eje horizontal se levantan perpendiculares en dos puntos a y b, el área bajo la curva delimitada por esas líneas indica la probabilidad de que la variable de interés, X, tome un valor cualquiera en ese intervalo. Puesto que la curva alcanza su mayor altura en torno a la media, mientras que sus "ramas" se extienden asintóticamente hacia los ejes, cuando una variable siga una distribución normal, será mucho más probable observar un dato cercano al valor medio que uno que se encuentre muy alejado de éste.La distribución normal posee ciertas propiedades importantes que conviene destacar:
y
es teóricamente posible. El área total bajo la curva es, por tanto, igual a 1.
. Según esto, para este tipo de variables existe una probabilidad de un 50% de observar un dato mayor que la media, y un 50% de observar un dato menor.
). Cuanto mayor sea
, más aplanada será la curva de la densidad.
.
y
(Figura 3). La media indica la posición de la campana, de modo que para diferentes valores de
la gráfica es desplazada a lo largo del eje horizontal. Por otra parte, la desviación estándar determina el grado de apuntamiento de la curva. Cuanto mayor sea el valor de
, más se dispersarán los datos en torno a la media y la curva será más plana. Un valor pequeño de este parámetro indica, por tanto, una gran probabilidad de obtener datos cercanos al valor medio de la distribución.
Como se deduce de este último apartado, no existe una única distribución normal, sino una familia de distribuciones con una forma común, diferenciadas por los valores de su media y su varianza. De entre todas ellas, la más utilizada es la distribución normal estándar, que corresponde a una distribución de media 0 y varianza 1. Así, la expresión que define su densidad se puede obtener de la ecuacion, resultando:
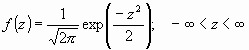
Es importante conocer que, a partir de cualquier variable X que siga una distribución, se puede obtener otra característica Z con una distribución normal estándar, sin más que efectuar la transformación:
Esta propiedad resulta especialmente interesante en la práctica, ya que para una distribuciónexisten tablas publicadas a partir de las que se puede obtener de modo sencillo la probabilidad de observar un dato menor o igual a un cierto valor z, y que permitirán resolver preguntas de probabilidad acerca del comportamiento de variables de las que se sabe o se asume que siguen una distribución aproximadamente normal.
EJEMPLO: supongamos que se sabe que el peso de los sujetos de una determinada población sigue una distribución aproximadamente normal, con una media de 80 Kg y una desviación estándar de 10 Kg. ¿Podremos saber cuál es la probabilidad de que una persona, elegida al azar, tenga un peso superior a 100 Kg?Denotando por X a la variable que representa el peso de los individuos en esa población, ésta sigue una distribución. Si su distribución fuese la de una normal estándar podríamos utilizar la tabla para calcular la probabilidad que nos interesa. Como éste no es el caso, resultará entonces útil transformar esta característica según la ecuacion, y obtener la variable:
para poder utilizar dicha tabla. Así, la probabilidad que se desea calcular será:
Como el área total bajo la curva es igual a 1, se puede deducir que:
Esta última probabilidad puede ser fácilmente obtenida a partir de la tabla, resultando ser. Por lo tanto, la probabilidad buscada de que una persona elegida aleatoriamente de esa población tenga un peso mayor de 100 Kg , es de 1–0.9772=0.0228, es decir, aproximadamente de un 2.3%.
De modo análogo, podemos obtener la probabilidad de que el peso de un sujeto esté entre 60 y 100 Kg:

APROXIMACIÓN DE LA DISTRIBUCIÓN BINOMIAL CON LA NORMAL

Es importante entender que, para un n finito, las distribuciones Binomial y Normal no coinciden.
Ahora bien, el estudio numérico del error cometido al aproximar la primera por la segunda, permite establecer algunas reglas generales para una Binomial con n finito:
n ≥ 30
|
0,1 ≤ p ≤ 0,9
|
aproximar a la Normal de media np, varianza np(1 − p)
|
n ≥ 30
|
0 < p < 0,1
|
aproximar a la Poisson con λ = np
|
n ≥ 30
|
0.9 < p < 1
|
aproximar la variable recíproca(*) a la Poisson con λ = n(1 − p)
|
n < 30
|
cualquier p
|
no aproximar, calcular con la variable original
|
(Si la Binomial está asociada al número de veces que aparece el suceso A de un total de n repeticiones del experimento, la variable recíproca corresponde a contar el número de veces que aparece el suceso contrario a A, y es por tanto una Binomial (n, 1 − p).
Por ejemplo:
- una Binomial (36, 0,5) es aproximadamente una Normal (18, 3).
- una Binomial (100, 0,9) es aproximadamente una Normal (90, 3).
- una Binomial (100, 0,01) es aproximadamente una Poisson (1).
- una Binomial (100, 0,95) se aproxima mediante su recíproca, una Binomial (100, 0,05), que es asintóticamente una Poisson(5).
Aquí puede consultarse un ejemplo de situación donde se aplica la aproximación Normal para simplificar el calculo.
En el cuadro siguiente se puede calcular el error numérico cometido al aproximar una Binomial mediante una Normal. Aparecen dos cantidades relacionadas con los n puntos de salto de la distribución: la discrepancia máxima y la discrepancia media.
Para obtener el error en un punto entre la verdadera función de distribución y la aproximación Normal puede recurrirse a la calculadora estadística, accesible mediante el botón correspondiente de la barra de navegación, y siguiendo el patrón del cálculo realizado aquí.
1) Desplazar la barra del número de ensayos n o la barra de la probabilidad p.
2) Comparar el comportamiento con y sin el reescalado de los ejes al aumentar ny al aumentar p.
3) Comparar las discrepancias al aumentar n y al aumentar p.
DISTRIBUCIÓN GAMMA
Este modelo es una generalización del modelo Exponencial ya que, en ocasiones, se utiliza para modelar variables que describen el tiempo hasta que se produce p veces un determinado suceso.
Su función de densidad es de la forma:
 Como vemos, este modelo depende de dos parámetros positivos: α y p. La función Γ(p) es la denominada función Gamma de Euler que representa la siguiente integral:
Como vemos, este modelo depende de dos parámetros positivos: α y p. La función Γ(p) es la denominada función Gamma de Euler que representa la siguiente integral:


El siguiente programa permite visualizar la forma de la función de densidad de este modelo (para simplificar, se ha restringido al caso en que p es un número entero).
Propiedades de la distribución Gamma
- Su esperanza es pα.
- Su varianza es pα2
- La distribución Gamma (α, p = 1) es una distribución Exponencial de parámetro α. Es decir, el modelo Exponencial es un caso particular de la Gamma con p = 1.
- Dadas dos variables aleatorias con distribución Gamma y parámetro α común
X ~ G(α, p1) y Y ~ G(α, p2)
se cumplirá que la suma también sigue una distribución Gamma
X + Y ~ G(α, p1 + p2).
Una consecuencia inmediata de esta propiedad es que, si tenemos k variables aleatorias con distribución Exponencial de parámetro α (común) e independientes, la suma de todas ellas seguirá una distribución G(α, k).
En realidad la distribución ji-cuadrada es la distribución muestral de s2. O sea que si se extraen todas las muestras posibles de una población normal y a cada muestra se le calcula su varianza, se obtendrá la distribución muestral de varianzas.

Pára estimar la varianza poblacionalo la desviación estándar, se necesita conocer el estadístico X2. Si se elige una muestra de tamaño n de una población normal con varianza , el estadístico:
tiene una distribución muestral que es una distribución ji-cuadrada con gl=n-1 grados de libertad y se denota X2 (X es la minúscula de la letra griega ji). El estadístico ji-cuadrada esta dado por:

donde n es el tamaño de la muestra, s2 la varianza muestral y la varianza de la población de donde se extrajo la muestra. El estadístico ji-cuadrada también se puede dar con la siguiente expresión:

Propiedades
- Los valores de X2 son mayores o iguales que 0.
- La forma de una distribución X2 depende del gl=n-1. En consecuencia, hay un número infinito de distribuciones X2.
- El área bajo una curva ji-cuadrada y sobre el eje horizontal es 1.
- Las distribuciones X2 no son simétricas. Tienen colas estrechas que se extienden a la derecha; esto es, están sesgadas a la derecha.
- Cuando n>2, la media de una distribución X2 es n-1 y la varianza es 2(n-1).
- El valor modal de una distribución X2 se da en el valor (n-3).
Prueba De hipotesis Estadisticas
Definiciones
a. Una hipótesis estadística es una suposición que se hace sobre la F. de D. de una variable aleatoria asociada a un experimento aleatorio.
b. Una prueba de hipótesis es un procedimiento que determina si la hipótesis en cuestión debe o no ser rechazada. Se anticipa que el no rechazo de una hipótesis no implica necesariamente su aceptación.
Para mas informacion, fuente:http://www.edutecne.utn.edu.ar/probabilidad/C11 %20Prueba%20Hipotesis%202303.pdf
Una posible hipotesis sugiere que el dioxido de carbono es el gas traza mas importante, cuanod se evalua el impacto en cambio climatico.
No hay comentarios:
Publicar un comentario